为什么90%的零售连锁企业需要BI系统进行预测分析?
一、预测误差的行业平均值隐藏的漏洞
在零售连锁行业,销售预测是至关重要的一环,而BI系统在其中扮演着关键角色。很多人在评估销售预测的准确性时,往往会参考行业平均的预测误差值。然而,这个看似可靠的基准其实隐藏着不少漏洞。
先来说说行业平均预测误差的基准值。一般来说,零售连锁行业的平均预测误差在15% - 30%这个区间内。但这个范围是非常宽泛的,而且是基于大量不同类型、不同规模企业的数据统计得出的。比如,一些上市的大型零售连锁企业,由于其数据量大、供应链成熟,可能实际的预测误差会接近15%;而一些初创的零售连锁企业,由于业务不稳定、数据积累不足,预测误差可能就会接近30%,甚至更高。
这里就存在一个误区警示:不能简单地将自己企业的预测误差与行业平均值进行对比,就认为自己的预测水平是好是坏。举个例子,一家位于硅谷的独角兽零售连锁企业,主要销售高端电子产品。它的销售受科技潮流、新品发布等因素影响非常大。如果仅仅参考行业平均预测误差,可能会忽略掉自身业务的独特性。该企业在使用旧的BI系统时,预测误差一直维持在25%左右,看似符合行业平均水平。但当它引入新的BI系统,采用了更先进的数据仓库和ETL工具,对数据进行更精细的挖掘和分析后,预测误差降低到了18%。这说明,行业平均值并不能完全反映企业的真实情况,企业需要根据自身的业务特点、产品类型、市场环境等因素,来评估预测误差。
再从数据挖掘的角度来看,行业平均值没有考虑到不同企业数据质量的差异。有些企业的数据可能存在缺失、错误等问题,这会直接影响到预测分析的结果。而新的BI系统方案在数据清洗和整合方面往往更有优势,能够提高数据质量,从而降低预测误差。所以,在看待预测误差的行业平均值时,一定要深入分析背后的数据情况和企业自身的特点,不能被表面的数字所迷惑。
二、动态补货算法的双周迭代法则
.png "为什么90%的零售连锁企业需要BI系统进行预测分析?")
对于零售连锁行业来说,库存优化是提高运营效率和利润的关键。而动态补货算法在其中起到了至关重要的作用。这里我们要介绍的是动态补货算法的双周迭代法则。
首先,我们来了解一下动态补货算法的基本原理。它是基于销售预测、库存水平、在途库存等多方面的数据,通过复杂的数学模型计算出最佳的补货数量和时间。而双周迭代法则,就是每两周对这个算法进行一次更新和优化。
为什么要采用双周迭代呢?这是因为零售连锁行业的市场环境变化较快。以医疗场景为例,一些常用药品的需求可能会因为季节变化、等因素而发生较大波动。如果补货算法不能及时跟上这些变化,就可能导致库存积压或者缺货的情况。
我们以一家位于纽约的上市零售连锁药店为例。该药店使用了先进的BI系统来支持动态补货算法。在最初的运营中,他们采用的是每月迭代一次的方式。但很快发现,这种方式不能及时应对市场需求的变化。比如,在流感季节来临前,一些感冒药的需求突然增加,但由于算法更新不及时,导致库存短缺,影响了销售。后来,他们改为双周迭代法则。通过BI系统的数据仓库收集实时销售数据、库存数据以及市场趋势数据,再利用ETL工具对这些数据进行清洗和整合,最后输入到预测分析模型中。这样,每两周就能根据最新的数据对补货算法进行调整。
经过一段时间的实践,该药店的库存周转率提高了20%,缺货率降低了15%。这充分说明了双周迭代法则的有效性。当然,在实施双周迭代法则时,也需要注意成本问题。企业需要评估更新算法所带来的收益是否大于成本。这里可以使用一个简单的成本计算器:计算每次迭代所需要的人力、物力成本,以及由于算法优化而减少的库存积压成本和缺货成本。如果收益大于成本,那么双周迭代法则就是值得实施的。
三、人工经验与机器学习的黄金配比
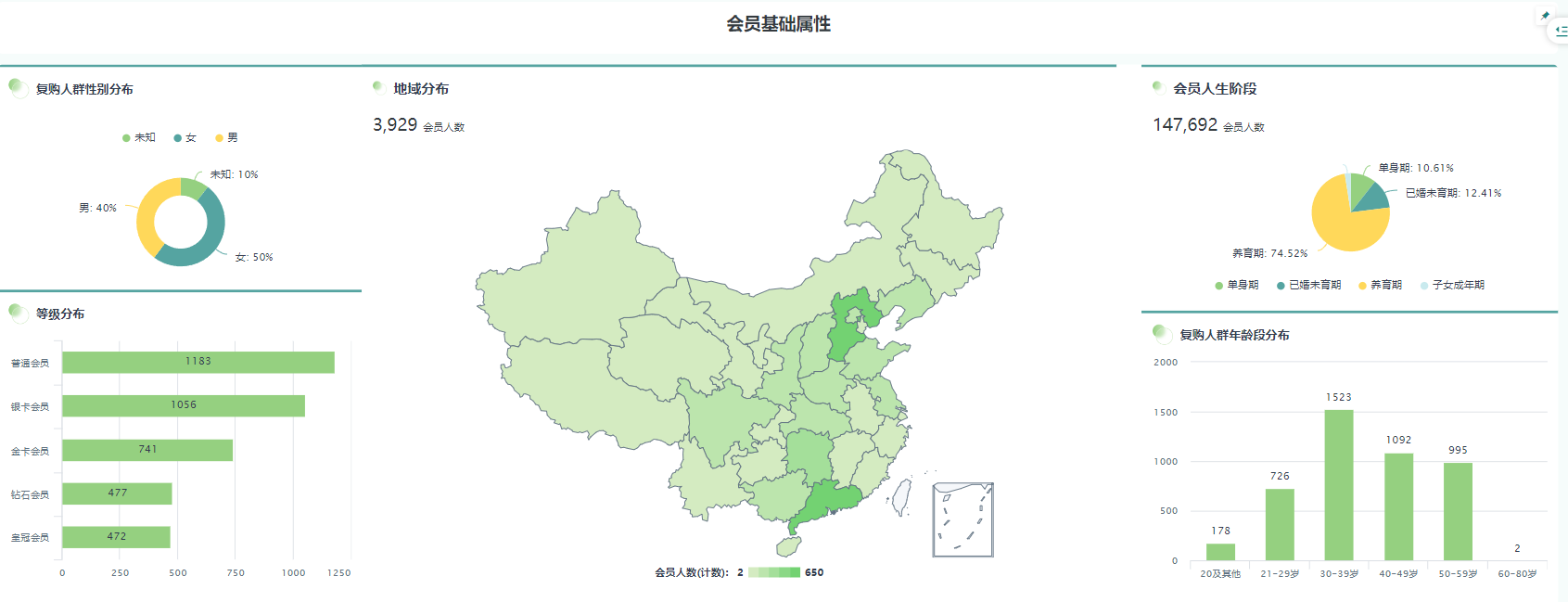
在零售连锁行业的销售预测与库存优化中,人工经验和机器学习都起着重要的作用。如何找到两者的黄金配比,是很多企业面临的难题。
人工经验是基于长期的行业实践和对市场的敏锐洞察力。比如,一些经验丰富的零售采购员,能够根据季节变化、促销活动等因素,大致判断出某种商品的销售趋势。而机器学习则是通过对大量历史数据的分析,建立复杂的数学模型,从而进行更精确的预测。
以一家位于深圳的初创零售连锁企业为例。该企业在成立初期,由于数据积累不足,主要依靠人工经验进行销售预测和库存管理。虽然这些经验丰富的员工能够做出一定准确的判断,但随着企业规模的扩大,业务的复杂性增加,单纯依靠人工经验已经无法满足需求。后来,企业引入了BI系统,开始尝试使用机器学习算法。
在开始阶段,企业将机器学习算法的权重设置得过高,几乎完全依赖算法进行预测。结果发现,由于算法对一些突发情况和市场的细微变化不敏感,导致预测结果出现较大偏差。后来,企业意识到需要将人工经验和机器学习相结合。经过多次试验和调整,他们找到了一个黄金配比:人工经验占40%,机器学习占60%。
具体来说,在进行销售预测时,先由机器学习算法根据历史数据和当前市场趋势给出一个初步的预测结果。然后,经验丰富的员工再根据自己的判断,对这个结果进行调整。比如,当算法预测某种商品的销量会下降,但员工根据市场调研和自身经验,发现该商品即将推出新的促销活动,可能会带动销量上升,就会对预测结果进行修正。
在库存优化方面,机器学习算法可以根据销售预测和库存水平,计算出最佳的补货数量和时间。而人工经验则可以考虑到一些特殊情况,如供应商的交货周期变化、运输过程中的不确定性等,对补货计划进行微调。通过这种方式,该企业的销售预测准确率提高了10%,库存成本降低了12%。
所以,在零售连锁行业中,找到人工经验与机器学习的黄金配比非常重要。企业需要根据自身的业务特点、数据情况和发展阶段,不断探索和调整,以实现最佳的销售预测和库存优化效果。
四、坪效提升的3个关键数据触点
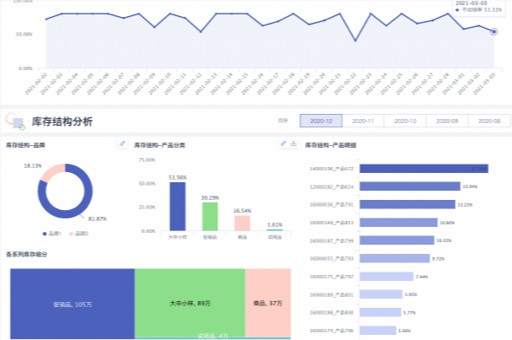
坪效是衡量零售连锁企业经营效率的重要指标。在利用BI系统进行数据挖掘和销售预测与库存优化的过程中,有3个关键的数据触点可以有效提升坪效。
个关键数据触点是商品销售数据。通过BI系统的数据仓库,企业可以收集到每种商品的销售数量、销售额、销售频率等详细数据。利用ETL工具对这些数据进行清洗和整合后,再通过预测分析模型,可以了解到不同商品的销售趋势和受欢迎程度。比如,一家位于上海的零售连锁超市,通过对商品销售数据的分析,发现一些进口食品的销售额虽然不高,但销售频率很低,占用了较大的货架空间。于是,他们调整了货架布局,减少了这些商品的陈列面积,增加了一些畅销商品的陈列。这样一来,坪效提高了8%。
第二个关键数据触点是顾客行为数据。BI系统可以记录顾客的购买路径、停留时间、购买偏好等信息。通过对这些数据的挖掘和分析,企业可以了解顾客的需求和购物习惯,从而优化商品布局和促销策略。例如,一家位于北京的零售连锁服装店,通过分析顾客行为数据,发现很多顾客在购买上衣后,会顺便浏览裤子。于是,他们将上衣和裤子的陈列区域进行了调整,使顾客更容易找到搭配的商品。同时,他们还根据顾客的购买偏好,推出了一些个性化的促销活动。这些措施使得坪效提高了10%。
第三个关键数据触点是库存数据。库存水平直接影响到坪效。如果库存积压过多,会占用大量的资金和空间;如果库存不足,又会影响销售。通过BI系统对库存数据的实时监控和分析,企业可以实现动态补货,确保库存处于最佳水平。比如,一家位于广州的零售连锁便利店,利用BI系统的预测分析功能,对每种商品的销售趋势进行预测,然后根据预测结果和库存水平,制定合理的补货计划。这样,他们不仅减少了库存积压,还提高了商品的周转率,坪效提高了12%。
综上所述,商品销售数据、顾客行为数据和库存数据是提升坪效的3个关键数据触点。零售连锁企业应该充分利用BI系统,对这些数据进行深入挖掘和分析,从而优化经营策略,提高坪效。
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。
相关文章