数据科学爆笑实录:传统整理VS智能清洗终极对决
一、数据整理:一场没有硝烟的
在数据科学的浩瀚宇宙中,数据整理犹如一场没有硝烟的。一边是手持Excel表格,对着屏幕抓耳挠腮的传统整理者,另一边则是驾驭智能清洗工具,谈笑间樯橹灰飞烟灭的数据科学家。这场对决,不仅是效率的比拼,更是思维方式的革新。
想象一下,一位财务分析师,每天面对成千上万的交易记录,需要手动核对每一笔账目,查找错误,修正偏差。这简直就是一场噩梦!而另一边,数据科学家利用智能清洗工具,几行代码就能搞定同样的工作,还能发现隐藏在数据中的规律和趋势。这,就是差距!
二、传统整理:那些年我们一起踩过的坑
(一)效率低下:时间都去哪儿了?
传统的数据整理方式,最大的问题就是效率低下。手动输入、复制粘贴、查找替换……每一个环节都耗时耗力。一个简单的数据清洗任务,可能需要花费数天甚至数周的时间。时间都去哪儿了?都耗费在重复劳动上了!
.png "数据科学爆笑实录:传统整理VS智能清洗终极对决")
更可怕的是,长时间的重复劳动容易让人产生疲劳和厌倦,导致错误率上升。辛辛苦苦整理出来的数据,结果却漏洞百出,这简直就是雪上加霜。
(二)人为错误:细节控也防不胜防
即使是最细心的“细节控”,也难以避免人为错误的发生。数据量越大,出错的概率就越高。一个小数点的偏差,一个字符的错误,都可能导致整个分析结果的偏差。
记得有一次,一位同事在整理销售数据时,不小心把一个订单的金额多输入了一个零。结果,整个月的销售额都虚高了10倍!老板差点乐疯了,以为公司业绩突飞猛进。直到后来发现错误,才虚惊一场。
(三)缺乏灵活性:牵一发而动全身
传统的数据整理方式,缺乏灵活性。一旦数据格式发生变化,或者需要增加新的字段,就需要重新设计整个整理流程。这简直就是牵一发而动全身,让人苦不堪言。
例如,当公司决定增加一个新的产品线时,就需要修改所有相关的报表和分析模型。如果使用传统的手工整理方式,这无疑是一项巨大的工程。
三、智能清洗:数据科学家的秘密武器
(一)自动化处理:解放双手,拥抱高效
智能清洗工具,最大的优势就是自动化处理。通过预先设定的规则和算法,可以自动完成数据清洗、转换、整合等任务。解放双手,拥抱高效!
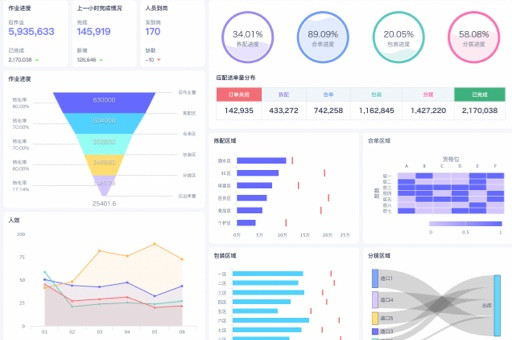
观远BI作为一站式智能分析平台,打通数据采集、接入、管理、开发、分析、AI建模到数据应用的全流程。其中的数据清洗功能,能够自动识别和纠正数据中的错误和不一致,大大提高了数据整理的效率和准确性。⭐⭐⭐⭐⭐
(二)智能化识别:让错误无处遁形
智能清洗工具,不仅可以自动处理数据,还能智能化识别数据中的错误和异常。通过机器学习算法,可以自动检测出数据中的离群值、重复值、缺失值等问题,让错误无处遁形。
观远BI的智能洞察功能,可以将业务分析思路转化为智能决策树,自动分析业务堵点,生成结论报告,辅助管理层决策。这就像一位经验丰富的侦探,能够从蛛丝马迹中发现真相。
(三)灵活可扩展:适应变化,拥抱未来
智能清洗工具,具有灵活可扩展的特性。可以根据不同的业务需求,自定义数据清洗规则和流程。即使数据格式发生变化,或者需要增加新的字段,也能轻松应对,拥抱未来。
观远BI支持实时数据Pro(高频增量更新调度)和中国式报表Pro(兼容Excel操作习惯)等功能,能够灵活应对各种数据处理场景,满足企业多样化的数据需求。👍🏻
四、数据标准化:智能转型的基石
(一)统一标准:消除信息孤岛
数据标准化是智能转型的基石。只有建立统一的数据标准,才能消除信息孤岛,实现数据的互联互通。如果没有统一的标准,即使拥有海量的数据,也无法发挥其真正的价值。
观远Metrics作为统一指标管理平台,能够帮助企业建立统一的数据标准,解决“同名不同义”问题,促进跨部门协作。❤️
(二)提升质量:为智能分析保驾护航
数据标准化能够提升数据质量,为智能分析保驾护航。只有高质量的数据,才能 menghasilkan accurate and reliable analytical results. 如果数据质量低劣,那么即使使用最先进的分析工具,也无法得出有价值的结论。
观远数据深耕数据分析与商业智能领域十余年,积累了丰富的行业经验和最佳实践。通过提供专业的数据标准化咨询服务,帮助企业提升数据质量,为智能分析奠定坚实的基础。
(三)降低成本:事半功倍,降本增效
数据标准化能够降低数据处理和分析的成本,实现事半功倍,降本增效。通过统一数据标准,可以减少重复劳动,提高工作效率,降低错误率。
观远数据致力于为零售、消费、金融、高科技、制造、互联网等行业的领先企业提供一站式数据分析与智能决策产品及解决方案,已服务、、、等500+行业领先客户。通过提供高效的数据标准化工具和服务,帮助客户降低数据处理成本,提高运营效率。
五、图书数据加工:一个生动的案例
(一)什么是图书数据加工?
图书数据加工是指对图书的各种信息进行整理、编辑、转换和标准化的过程。包括书名、作者、出版社、ISBN、主题词、摘要等信息的录入、校对、清洗和转换。图书数据加工的目的是为了方便图书的检索、分类、管理和利用。
例如,图书馆需要对新入库的图书进行数据加工,以便读者可以通过图书馆的检索系统找到所需的图书。出版社需要对图书的元数据进行加工,以便在电商平台上销售图书。
(二)图书数据加工的意义
图书数据加工的意义在于:提高图书的检索效率、方便图书的分类管理、促进图书的数字化传播、提升图书的利用价值。
如果没有经过数据加工的图书,读者很难通过关键词检索找到所需的图书。图书馆管理员也很难对图书进行分类和管理。出版社也无法将图书的信息有效地传递给读者。
(三)图书数据加工如何进行?
图书数据加工通常包括以下几个步骤:
- 数据采集:从图书的封面、目录、版权页等处采集图书的信息。
- 数据录入:将采集到的信息录入到数据库中。
- 数据校对:对录入的信息进行校对,确保准确无误。
- 数据清洗:对录入的信息进行清洗,删除错误和不规范的数据。
- 数据转换:将录入的信息转换为统一的格式。
- 数据标准化:对录入的信息进行标准化,建立统一的数据标准。
(四)图书数据加工的步骤
图书数据加工的步骤可以概括为:采集、录入、校对、清洗、转换、标准化。
在实际操作中,可以使用专业的图书数据加工工具,例如OCR识别软件、数据清洗软件、数据转换软件等。也可以委托专业的图书数据加工公司进行数据加工。
六、观远BI:数据科学家的得力助手
在数据科学的道路上,选择一款合适的工具至关重要。观远BI作为一站式智能分析平台,是数据科学家的得力助手。它不仅能够帮助你高效地完成数据清洗、转换、整合等任务,还能让你深入挖掘数据中的价值,发现隐藏的规律和趋势。
观远BI的最新版本6.0包含四大模块:BI Management(企业级平台底座)、BI Core(聚焦端到端易用性)、BI Plus(解决具体场景化问题)、BI Copilot(结合大语言模型)。通过这些模块的协同工作,能够帮助企业实现敏捷决策、跨部门协作和生成式AI。
| 功能模块 | 主要特点 | 应用场景 |
|---|---|---|
| BI Management | 企业级平台底座,保障安全稳定的大规模应用。 | 大型企业数据分析平台建设 |
| BI Core | 聚焦端到端易用性,业务人员经短期培训即可自主完成80%的数据分析。 | 业务部门自助式数据分析 |
| BI Plus | 解决具体场景化问题(如实时数据分析、复杂报表生成)。 | 特定业务场景深度分析 |
| BI Copilot | 结合大语言模型,支持自然语言交互、智能生成报告,降低使用门槛。 | 智能数据分析助手 |
七、结语:拥抱智能,决胜未来
数据科学的时代已经来临。拥抱智能,才能决胜未来。让智能清洗工具成为你的秘密武器,让观远BI成为你的得力助手,一起在数据科学的道路上,披荆斩棘,勇往直前!
本文编辑:豆豆,来自Jiasou TideFlow AI SEO 创作
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。
相关文章