如何利用SPSS进行均值聚类分析
在数据分析领域,聚类分析是一种常用的无监督学习方法,能够将数据集中的观测对象划分为不同的群组。均值聚类分析是聚类分析中一种常见的方法,它通过计算对象间的欧氏距离,并使用迭代的方法来确定最优的聚类中心。

SPSS(Statistical Package for the Social Sciences)是一款专业的统计分析软件,它提供了丰富的功能和工具,可以用于数据分析、数据挖掘和预测建模等领域。在SPSS中,进行均值聚类分析非常简单。
首先,我们需要准备一组数据集,每个观测对象对应一条数据记录,每个变量对应观测对象的某个特征。然后,打开SPSS软件,在“分析”菜单中选择“分类聚类”选项,再选择“均值”方法。
接下来,将要进行聚类分析的变量选中并移动到“变量”框中,然后点击“设置”按钮,设置聚类分析的参数。例如,可以选择聚类结果的个数、迭代的次数和初始聚类中心的选择方法。
完成设置后,点击“确定”按钮,SPSS会自动进行均值聚类分析,并在输出窗口中显示聚类结果。聚类结果通常包括每个观测对象所属的聚类群组、聚类中心的均值和聚类对象的数量等信息。
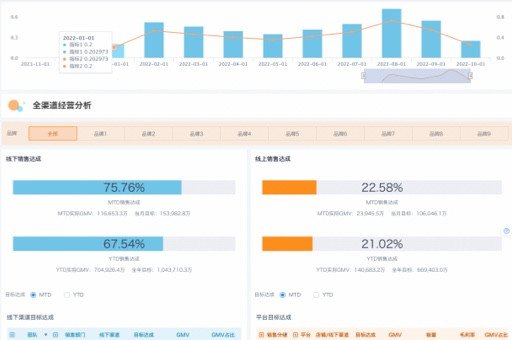
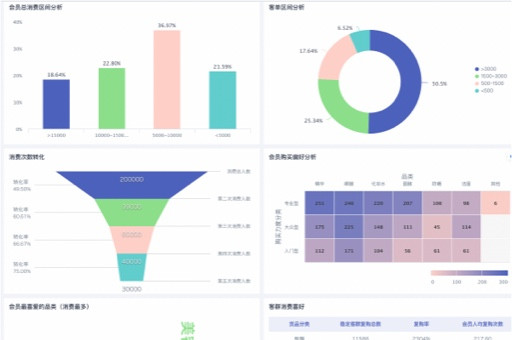
为了更好地理解和解释聚类结果,我们可以通过数据可视化的方式将聚类结果呈现出来。SPSS提供了多种数据可视化的功能,例如散点图、柱状图和雷达图等。我们可以根据需要选择合适的可视化方式,使得聚类结果更加直观、易于理解。
总之,利用SPSS进行均值聚类分析是一种简单而有效的方法,它可以帮助我们对数据集进行分组,并发现不同观测对象之间的相似性和差异性。通过数据可视化,我们可以更好地理解和解释聚类结果,为后续的分析和决策提供有力的支持。
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。
相关文章